Using FFmpeg with Google Cloud Speech-to-Text
Google Cloud Speech-to-Text is a fully managed service that converts speech to text in real time. It can be used to transcribe audio and video files, create subtitles for videos, and build voice-activated applications.
The service supports a wide range of audio formats, including WAV, MP3, and AAC. It can also transcribe audio in a variety of languages, including English, Spanish, French, German, Japanese and many more
Google Cloud Speech-to-Text is easy to use. You can simply upload your audio file to the service, and it will automatically transcribe it into text. You can also use the service to transcribe live audio, such as a phone call or a meeting. Speech-to-Text samples are given here for V1 and V2.
Problem
However, what if the input audio encoding is not supported by the STT API?
Supported audio encodings are given at https://cloud.google.com/speech-to-text/docs/encoding
Fortunately, there are a number of third-party tools available to assist with encoding conversion.
FFmpeg is a popular multimedia framework for handling audio and video data. It can be used to encode, decode, transcode, and stream audio and video content. In this blog, we will demonstrate how to use FFmpeg in various scenarios to obtain the correct encoding for calling an STT API.
- Running it locally from the command line
- Invoking it through a Python program
- Building a container image with GCP buildpacks and FFmpeg
- Running from Vertex AI Workbench
Running it locally from the command line
Download ffmpeg software from – https://www.ffmpeg.org/download.html and install it.
Take a sample input audio source is encoded in “acelp.kelvin” which is not supported by STT API
To determine how the audio source is encoded, run ffmpeg -i input.wav output will shown the encoding
Stream #0:0: Audio: acelp.kelvin (5[1][0][0] / 0x0135), 8000 Hz, 2 channels, s16p, 17 kb/s
Run below command to change the encoding to “pcm_s161e”
ffmpeg -i "input.wav " -f wav -bitexact -acodec pcm_s16le -ac 2 ”output.wav"
The output of the ffmpeg -i outpt.wav command indicates that the encoding of the file has been changed and that the file is now ready to be passed through the STT API.
Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 22050 Hz, 2 channels, s16, 705 kb/s
For a full list of ffmpeg options see http://ffmpeg.org/documentation.html
Invoking it through a Python program
Add the version of ffmpeg to your requirements.txt file and run pip install -r requirements.txt
ffmpeg-python==0.2.0
The following Python code snippet takes an input file and the output audio is encoded in pcm_s16le.
Input files can be either local to the machine or stored in a GCS Bucket. If files are stored in a GCS Bucket, they must first be downloaded to the machine where the ffmpeg software is running, and then re-uploaded after the encoding is modified.lang-py
def convert_using_ffmpeg(input_file, output_file):
try:
(
ffmpeg
.input(input_file)
.output(output_file, format='wav', acodec='pcm_s16le', ac=2)
.run(overwrite_output=True)
)
except Exception as e:
logging.error(e)
return False
return True
Building a container image with GCP buildpacks and FFmpeg
Google Cloud’s buildpacks transforms your application source code into container images that are ready for production. Buildpacks use a default builder but you can customize run images to add the packages that are required for building your service.
1.1. Create a Dockerfile
The first step is to create a Dockerfile (builder.Dockerfile). This file will describe how to build a base ffmpeg image.
FROM gcr.io/buildpacks/builder
USER root
RUN apt-get -y update
RUN apt-get install -y ffmpeg
This Dockerfile will use the default “gcr.io/buildpacks/builder” image as a base image. It will then install the FFmpeg package using the apt-get command.
1.2. Build the Container Image
Once you have created your Dockerfile, you can build the container image using the following commands
docker build -t ffmpeg-run-image:1 -f builder.Dockerfile .
pack build ffmpeg-service-image --builder gcr.io/buildpacks/builder:latest --run-image ffmpeg-run-image:1
1.3. Push the Container Image
Once you have built the base ffmpeg image, you can run it using the following command
docker tag ffmpeg-service-image:latest gcr.io/<PROJECT_ID/ffmpeg-service-image:latest
docker push gcr.io/<PROJECT_ID/ffmpeg-service-image:latest
Your image is now ready with the ffmpeg software. Instead of build packs, you can use any image and follow the standard container build process to include ffmpeg.
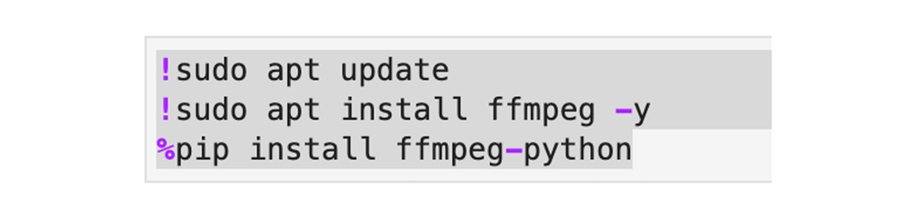
Running from Vertex AI Workbench (Ubuntu)
Running on a Vertex Jupyter Workbench is similar to running a Python program locally. From a Jupyter notebook, FFmpeg can be installed using sudo and the Python code snippet given above can be executed as is. The installation commands for ffmpeg may vary depending on the environment of your notebook.
Conclusion
Encoding conversion is a straightforward process; the platform of choice for the conversion process is determined by the number and size of the audio files and the amount of conversion needed. Converting a small number of files can be accomplished using command line or running a Python program locally. If this is a recurring task, building an image and using a serverless platform like Cloud Run are ideal. Vertex Workbench is more efficient in processing audio files of increasing size, particularly when parallel processing is needed.
FFmpeg requires that audio files be in the same location as the software, which can lead to performance issues when processing large audio files, especially when audio files are stored in a GCS Bucket. To avoid this, it is recommended to choose a processing platform on GCP and that is in the same region as the GCS Bucket where the audio files are stored. This will reduce the amount of time it takes to process the files, as the data does not need to be transferred between regions.

{kind=link}