How Google scales ad personalization with Bigtable
Cloud Bigtable is a popular and widely used key-value database available on Google Cloud. The service provides scale elasticity, cost efficiency, excellent performance characteristics, and 99.999% availability SLA. This has led to massive adoption with thousands of customers trusting Bigtable to run a variety of their mission-critical workloads.
Bigtable has been in continuous production usage at Google for more than 15 years now. It processes more than 5 billion requests per second at peak and has more than 10 exabytes of data under management. It’s one of the largest semi-structured data storage services at Google.
One of the key use cases for Bigtable at Google is ad personalization. This post describes the central role that Bigtable plays within ad personalization.
Ad personalization
Ad personalization aims to improve user experience by presenting topical and relevant ad content. For example, I often watch bread-making videos on YouTube. If ads personalization is enabled in my ad settings, my viewing history could indicate to YouTube that I’m interested in baking as a topic and would potentially be interested in ad content related to baking products
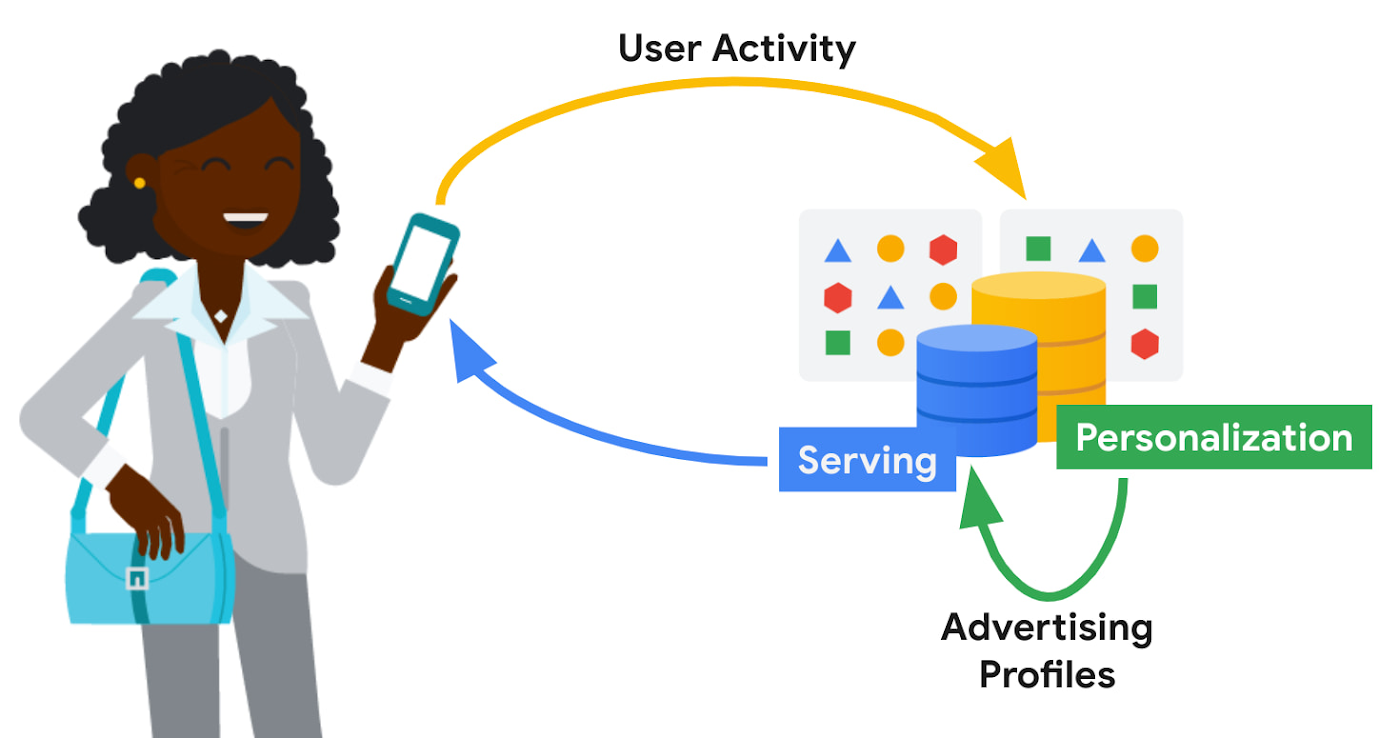
Ad personalization requires large-scale data processing in near real-time for timely personalization with strict controls for user data handling and retention. System availability needs to be high, and serving latencies need to be low due to the narrow window within which decisions need to be made on what ad content to retrieve and serve. Sub-optimal serving decisions (e.g. falling back to generic ad content) could potentially impact user experience. Ad economics requires infrastructure costs to be kept as low as possible.
Google’s ad personalization platform provides frameworks to develop and deploy machine learning models for relevance and ranking of ad content. The platform supports both real-time and batch personalization. The platform is built using Bigtable, allowing Google products to access data sources for ads personalization in a secure manner that is both privacy and policy compliant, all while honoring users’ decisions about what data they want to provide to Google
The output from personalization pipelines, such as advertising profiles are stored back in Bigtable for further consumption. The ad serving stack retrieves these advertising profiles to drive the next set of ad serving decisions.
Some of the storage requirements of the personalization platform include:
- Very high throughput access for batch and near real-time personalization
- Low latency (<20 ms at p99) lookup for reads on the critical path for ad serving
- Fast (i.e. in the order of seconds) incremental update of advertising models in order to reduce personalization delay
Bigtable
Bigtable’s versatility in supporting both low-cost, high-throughput access to data for offline personalization as well as consistent low-latency access for online data serving makes it an excellent fit for the ads workloads.
Personalization at Google-scale requires a very large storage footprint. Bigtable’s scalability, performance consistency and low cost required to meet a given performance curve are key differentiators for these workloads.
Data model
The personalization platform stores objects in Bigtable as serialized protobufs keyed by Object ids. Typical data sizes are less than 1 MB and serving latency is less than 20 ms at p99.
Data is organized as corpora, which correspond to distinct categories of data. A corpus maps to a replicated Bigtable.
Within a corpus, data is organized as DataTypes, logical groupings of data. Features, embeddings, and different flavors of advertising profiles are stored as DataTypes, which map to Bigtable column families. DataTypes are defined in schemas which describe the proto structure of the data and additional metadata indicating ownership and provenance. SubTypes map to Bigtable columns and are free-form.
Each row of data is uniquely identified by a RowID, which is based on the Object ID. The personalization API identifies individual values by RowID (row key), DataType (column family), SubType (column part), and Timestamp.
Consistency
The default consistency mode for operations is eventual. In this mode, data from the Bigtable replica nearest to the user is retrieved, providing the lowest median and tail latency.
Reads and writes to a single Bigtable replica are consistent. If there are multiple replicas of Bigtable in a region, traffic spillover across regions is more likely. To improve the likelihood of read-after-write consistency, the personalization platform uses a notion of row affinity. If there are multiple replicas in a region, one replica is preferentially selected for any given row, based on a hash of the Row ID.
For lookups with stricter consistency requirements, the platform first attempts to read from the nearest replica and requests that Bigtable return the current low watermark (LWM) for each replica. If the nearest replica happens to be the replica where the writes originated, or if the LWMs indicate that replication has caught up to the necessary timestamp, then the service returns a consistent response. If replication has not caught up, then the service issues a second lookup—this one targeted at the Bigtable replica where writes originated. That replica could be distant and the request could be slow. While waiting for a response, the platform may issue failover lookups to other replicas in case replication has caught up at those replicas.
Bigtable replication
The Ads personalization workloads use a Bigtable replication topology with more than 20 replicas, spread across four continents.
Replication helps address the high availability needs for ad serving. Bigtable’s zonal monthly uptime percentage is in excess of 99.9%, and replication coupled with a multi-cluster routing policy allows for availability in excess of 99.999%.
A globe-spanning topology allows for data placement that is close to users, minimizing serving latencies. However, it also comes with challenges such as variability in network link costs and throughputs. Bigtable uses Minimum Spanning Tree-based routing algorithms and bandwidth-conserving proxy replicas to help reduce network costs.
For ads personalization, reducing Bigtable replication delay is key to lowering the personalization delay (the time between a user’ action and when that action has been incorporated into advertising models to show more relevant ads to the user). Faster replication is preferred but we also need to balance serving traffic against replication traffic and make sure low-latency user-data serving is not disrupted due to incoming or outgoing replication traffic flows. Under the hood, Bigtable implements complex flow control and priority boost mechanisms to manage global traffic flows and to balance serving and replication traffic priorities.
Workload Isolation
Ad personalization batch workloads are isolated from serving workloads by pinning a given set of workloads onto certain replicas; some Bigtable replicas exclusively drive personalization pipelines while others drive user-data serving. This model allows for a continuous and near real-time feedback loop between serving systems and offline personalization pipelines, while protecting the two workloads from contending with each other.
For Cloud Bigtable users, AppProfiles and cluster-routing policies provide a way to confine and pin workloads to specific replicas to achieve coarse-grained isolation.
Data residency
By default, data is replicated to every replica—often spread out globally—which is wasteful for data that is only accessed regionally. Regionalization saves on storage and replication costs by confining data to the region where it is most likely to be accessed. Compliance with regulations mandating that data pertaining to certain subjects are physically stored within a given geographical area is also vital.
The location of data can be either implicitly determined by the access location of requests or through location metadata and other product signals. Once the location for a user is determined, it is stored in a location metadata table which points to the Bigtable replicas that read requests should be routed to. Migration of data based on row-placement policies happens in the background, without downtime or serving performance regressions.
Conclusion
In this blog post, we looked at how Bigtable is used within Google to support an important use case—modeling user intent for ad personalization.
Over the past decade, Bigtable has scaled as Google’s personalization needs have scaled by orders of magnitude. For large-scale personalization workloads, Bigtable offers low cost storage with excellent performance characteristics. It seamlessly handles global traffic flows with simple user configurations. Its ease at handling both low-latency serving and high-throughput batch computations make it an excellent option for lambda-style data processing pipelines.
Google will continue to drive high levels of investment to further lower costs, improve performance, and bring new features to make Bigtable an even better choice for personalization workloads.
Learn more
To get started with Bigtable, try it out with a Qwiklab and learn more about the product here.