Google Cloud launches new models for more accurate Speech AI
With voice continuing to emerge as the new frontier in human-computer interaction, many enterprises may seek to level up their technology and present consumers with speech recognition systems that more reliably and accurately recognize what their users are saying. Think about it: higher speech recognition quality can enable people to talk to their applications and devices the way they would talk to their friends, their doctors, or other people they interact with.
This opens up a world of use cases, from hands-free applications for drivers to voice assistants across smart devices. Moreover, beyond giving machines instructions, accurate speech recognition enables live captions in video meetings, insights from live and recorded conversations, and much more. In the five years since Google launched their Speech-to-Text (STT) API, Google have seen customer enthusiasm for the technology increase, with the API now processing more than 1 billion minutes of speech each month. That’s equivalent to listening to Wagner’s 15-hour Der Ring des Nibelungen over 1.1 million times, and assuming around 140 words spoken per minute, it’s enough each month to transcribe Hamlet (Shakespeare’s longest play) nearly 4.6 million times.
That’s why today, they’re announcing the availability of their newest models for the STT API. Google are also announcing a new model tag, “latest,” to help you access them. A major improvement in their technology, these models can help improve accuracy across 23 of the languages and 61 of the locales STT supports, helping you to more effectively connect with your customers at scale through voice.
New models for better accuracy and understanding
The effort towards this new neural sequence-to-sequence model for speech recognition is the latest step in an almost eight-year journey that required extensive amounts of research, implementation, and optimization to provide the best quality characteristics across different use cases, noise environments, acoustic conditions, and vocabularies. The architecture underlying the new model is based on cutting-edge ML techniques and lets us leverage our speech training data more efficiently to see optimized results.
So what’s different about this model versus the one currently in production?
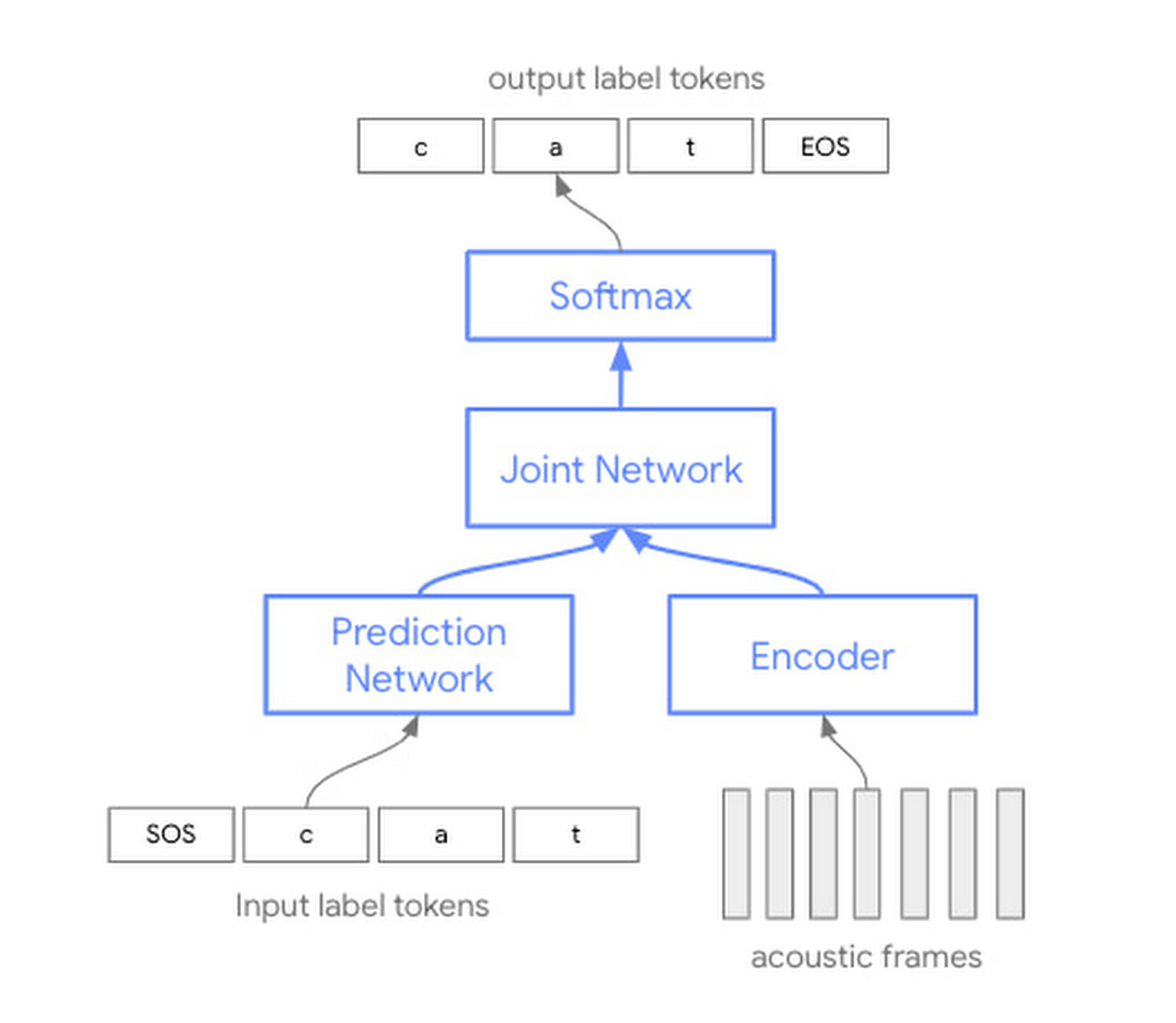
For the past several years, automated speech recognition (ASR) techniques have been based on separate acoustic, pronunciation, and language models. Historically, each of these three individual components was trained separately, then assembled afterwards to do speech recognition.
The conformer models that they’re announcing today are based on a single neural network. As opposed to training three separate models that need to be subsequently brought together, this approach offers more efficient use of model parameters. Specifically, the new architecture augments a transformer model with convolution layers (hence the name con-former), allowing us to capture both the local and global information in the speech signal.
Enterprises and developers alike will instantly see out-of-box quality improvements when using the STT API, and while you can always tune your model for better performance, the benefits of this new architecture can be felt without any initial tuning necessary. With the model’s expanded support for different kinds of voices, noise environments, and acoustic conditions, you can produce more accurate outputs in more contexts, letting you more quickly, easily, and effectively embed voice technologies in applications.
If you are building speech control interfaces where users speak to their smart devices and applications, these improvements can let your users speak to these interfaces more naturally and in longer sentences. Without having to worry about whether or not their speech will be accurately captured, your users can establish better relationships with the machines and applications they interact with—and with your businesses as the brand behind the experience.
Early adopters of the new models are already seeing benefits. “Spotify worked closely with Google on bringing our brand new voice interface, ‘Hey Spotify,’ to customers across our mobile apps and Car Thing. The increases in quality and especially noise robustness from the latest models, in addition to Spotify’s work on NLU and AI, are what make it possible to have these services work so well for so many users,” said Daniel Bromand, Head of Technology Hardware Products at Spotify.
As previously mentioned, to support these models while still maintaining the existing ones, the STT API is also introducing these models under a new identifier—“latest.” When specifying “latest long” or “latest short,” you will get access to Google’s latest conformer models as they continue to update them. “Latest long” is specifically designed for long-form spontaneous speech, similar to the existing “video” model. “Latest short,” on the other hand, gives great quality and great latency on short utterances like commands or phrases.
They are committed to continuously updating these models in order to bring you the latest speech recognition research from Google. The features of these models may differ slightly from those of existing ones such as “default” or “command_and_search,” but they are all eligible for the same stability and support guarantees as the rest of the GA STT API services. For exact feature availability, check the documentation.